Qué es la deduplicación en el almacenamiento de datos de backup
Las grandes infraestructuras virtuales actuales generan una enorme cantidad de datos. Esto conlleva un aumento de los datos de backup y del gasto en infraestructura de almacenamiento de backups, que incluye los appliance de backups y su mantenimiento. Por este motivo, los administradores de red buscan formas de ahorrar espacio de almacenamiento a la hora de hacer backups frecuentes de máquinas y aplicaciones críticas.
Una de las técnicas más utilizadas es la deduplicación de backups. En esta entrada del blog se explica qué es la deduplicación de datos, los tipos de deduplicación y los casos de uso, con especial atención a los backups.

¿Qué es la deduplicación?
La deduplicación de datos es una tecnología de optimización de la capacidad de almacenamiento. La deduplicación de datos consiste en leer los datos de origen y los que ya están almacenados para transferir o guardar sólo bloques de datos únicos. Se mantienen las referencias a los datos duplicados. Al utilizar esta tecnología para evitar duplicados en un volumen, puede ahorrar espacio en disco y reducir la sobrecarga de almacenamiento.
Orígenes de la deduplicación de datos
Los predecesores de la deduplicación de datos son los algoritmos de compresión LZ77 y LZ78, introducidos en 1977 y 1978 respectivamente. Consisten en sustituir las secuencias de datos repetidas por referencias a las originales.
Este concepto influyó en otros métodos de compresión populares. El más conocido es DEFLATE, que se utiliza en los formatos de imagen PNG y archivos ZIP. Veamos ahora cómo funciona la deduplicación con los backups de máquinas virtuales y cómo ayuda exactamente a ahorrar espacio de almacenamiento y costes de infraestructura.
¿Qué es la deduplicación en el backup?
Durante un backup, la deduplicación de datos comprueba si hay bloques de datos idénticos entre el almacenamiento de origen y el repositorio de backups de destino. Los duplicados no se copian y se crea una referencia, o puntero, a los bloques de datos existentes en el almacenamiento de backups de destino.
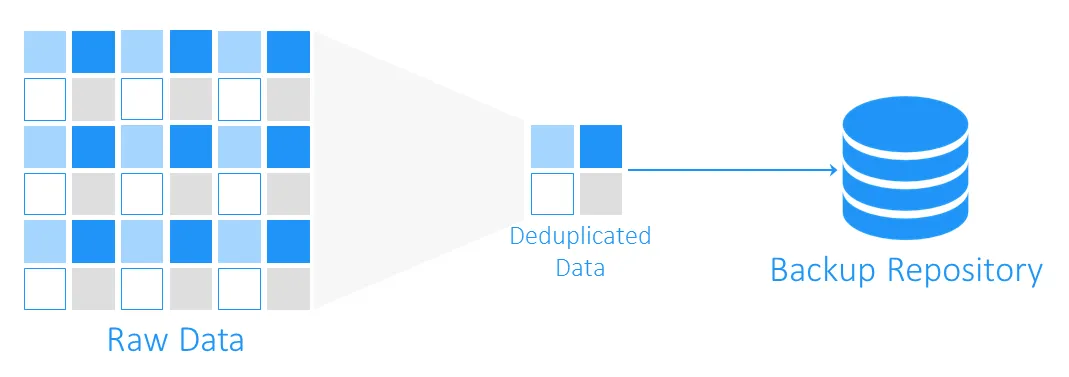
¿Cuánto espacio puede ahorrarle la deduplicación de datos?
Para entender cuánto espacio de almacenamiento se puede ganar con la deduplicación, veamos un ejemplo. Los requisitos mínimos del sistema para instalar Windows Server 2016 son al menos 32 GB de espacio libre en disco. Si tienes diez máquinas virtuales ejecutando este sistema operativo, los backups sumarán al menos 320 GB, y esto es sólo un sistema operativo limpio sin ninguna aplicación o base de datos en él.
Lo más probable es que si necesita desplegar más de una máquina virtual (VM) con el mismo sistema, utilice una plantilla, y esto significa que inicialmente tendrá diez máquinas idénticas. Y esto también significa que obtendrá 10 conjuntos de bloques de datos duplicados. En este ejemplo, tendrá una relación de ahorro de espacio de almacenamiento de 10:1. En general, un ahorro de entre 5:1 y 10:1 se considera bueno.
Ratio de deduplicación de datos
El ratio de deduplicación de datos es una métrica utilizada para medir el tamaño de los datos originales frente al tamaño de los datos una vez eliminadas las partes redundantes. Esta métrica permite evaluar la eficacia del proceso de deduplicación de datos. Para calcular el valor, debe dividir la cantidad de datos antes de la deduplicación por el espacio de almacenamiento consumido por estos datos después de ser deduplicados.
Por ejemplo, el ratio de deduplicación de 5:1 significa que se pueden almacenar cinco veces más datos en el almacenamiento de backups de lo que se necesitaría para almacenar los mismos datos sin deduplicación.
Debe determinar el ratio de deduplicación y la reducción del espacio de almacenamiento. A veces se confunden estos dos parámetros. Los ratios de deduplicación no cambian proporcionalmente a los beneficios de la reducción de datos, ya que a partir de cierto punto entra en juego la ley de los rendimientos decrecientes. Véase el gráfico siguiente.
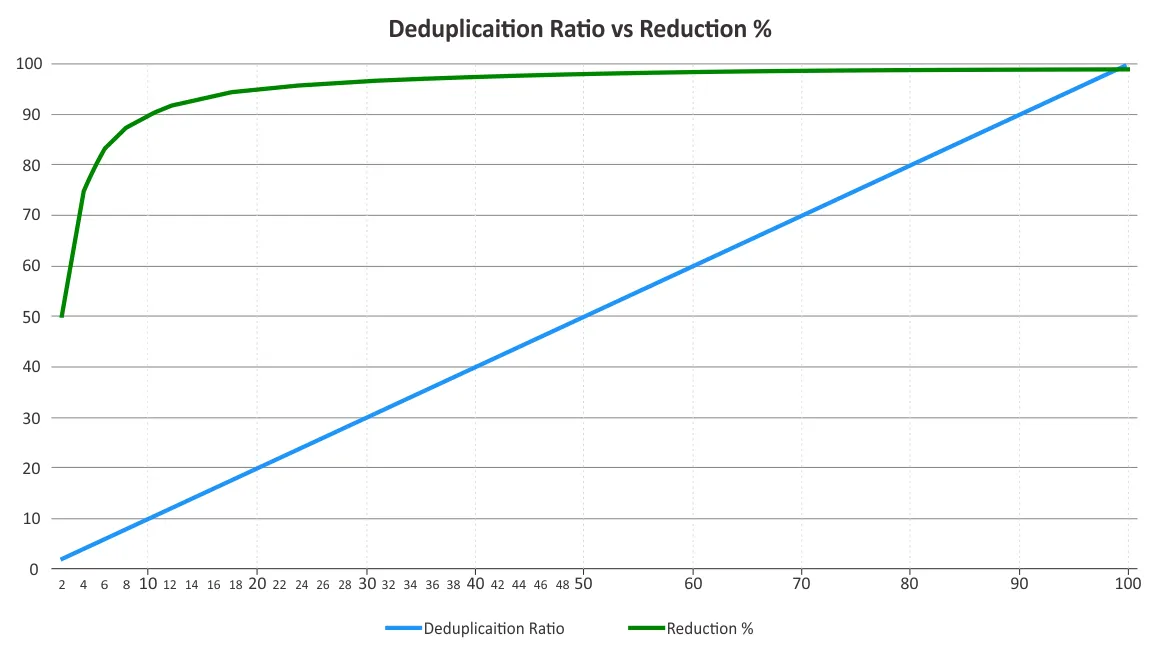
Esto significa que las ratios más bajas pueden suponer un ahorro más significativo que las más altas. Por ejemplo, un ratio de deduplicación de 50:1 no es cinco veces mejor que un ratio de 10:1. La relación 10:1 proporciona una reducción del 90% del espacio de almacenamiento consumido, mientras que la relación 50:1 aumenta este valor hasta el 98%, dado que ya se ha eliminado la mayor parte de la redundancia. Para más información sobre cómo se calculan estos porcentajes, puede consultar el documento de la Storage Networking Industry Association (SNIA) sobre deduplicación de datos.
Factores que influyen en la eficacia de la deduplicación de datos
Es difícil predecir la eficacia de la reducción de datos hasta que éstos se deduplican realmente, debido a varios factores. A continuación se enumeran algunos de los factores que influyen en la reducción de datos cuando se utiliza la deduplicación:
- Tipos y políticas de backups de datos. La deduplicación para backups completos es más eficaz que para backups incrementales o diferenciales.
- Tasa de cambio. Si hay muchos cambios de datos de los que hacer backup de, entonces el ratio de deduplicación es menor.
- Ajustes de retención. Cuanto más tiempo se guarden los backups de datos en el almacenamiento de backups, más eficaz puede ser la deduplicación de datos en este almacenamiento.
- Tipo de datos. La deduplicación para archivos en los que los datos ya han sido comprimidos, como JPG, PNG, MPG, AVI, MP4, ZIP, RAR, etc., no es efectiva. Lo mismo ocurre con los datos ricos en metadatos y cifrados. Los tipos de datos que contienen partes repetitivas son mejores para la deduplicación.
- Alcance de los datos. La deduplicación de datos es más eficaz para un gran volumen de datos. La desduplicación global puede ahorrar más espacio de almacenamiento en comparación con la desduplicación local.
Nota: La deduplicación local funciona en un único nodo/dispositivo de disco. La desduplicación global analiza todo el conjunto de datos en todos los nodos/dispositivos de disco para eliminar los datos duplicados. Si tiene varios nodos con la deduplicación local activada en cada uno de ellos, la deduplicación no sería tan eficiente como con la deduplicación global activada para ellos.
- Software y hardware. La combinación de soluciones de software y hardware de deduplicación puede ofrecer mejores ratios de deduplicación que el software por sí solo. Por ejemplo, la solución de backup de NAKIVO ofrece integración con appliance de desduplicación HP StoreOnce, Dell EMC Data Domain y NEC HYDRAstor para conseguir ratios de desduplicación de hasta 17:1.
Técnicas de deduplicación de backups
Las técnicas de deduplicación de backups pueden clasificarse en función de lo siguiente:
- Dónde se realiza la deduplicación de datos
- Una vez realizada la deduplicación
- Cómo se realiza la deduplicación
Dónde se realiza la deduplicación de datos
La deduplicación de backups puede hacerse en el lado de origen o en el de destino, y esas técnicas se denominan deduplicación en el lado de origen y deduplicación en el lado de destino, respectivamente.
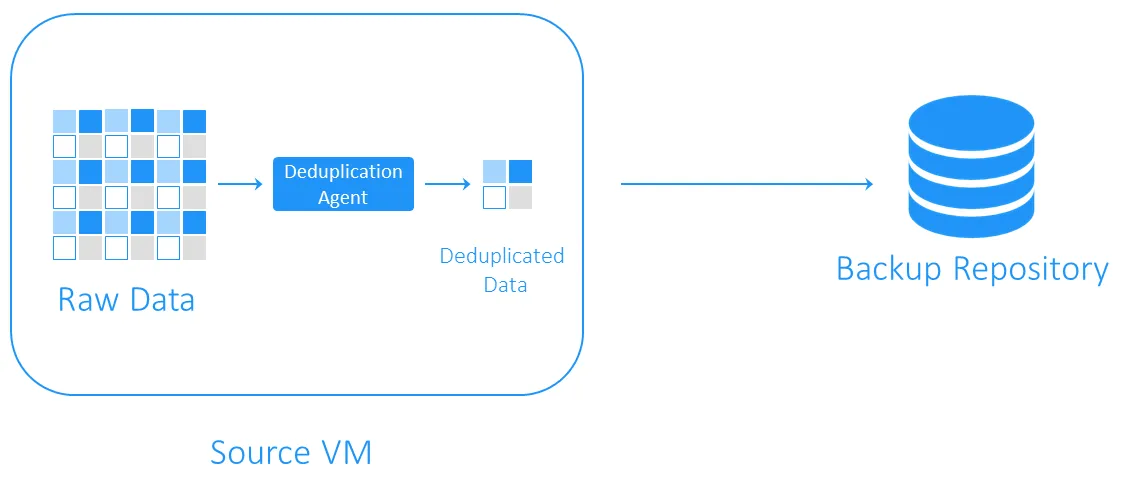
Deduplicación en origen
La deduplicación en origen disminuye la carga de la red porque se transfieren menos datos durante el backup. Sin embargo, requiere la instalación de un agente de deduplicación en cada máquina virtual o en cada host. El otro inconveniente es que la deduplicación en origen puede ralentizar las máquinas virtuales debido a los cálculos necesarios para la identificación de bloques de datos duplicados.
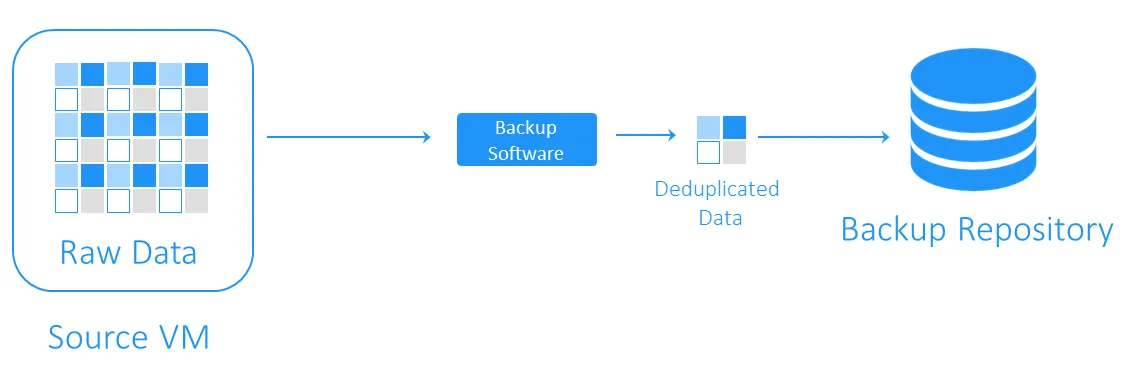
Deduplicación en el destino
La deduplicación del lado del destino transfiere primero los datos al repositorio de backups y luego realiza la deduplicación. Las tareas informáticas pesadas las realiza el software responsable de la deduplicación.
Cuando se realiza la deduplicación de datos
La deduplicación de backups puede ser inline o post-processing.
- La deduplicación en línea comprueba si hay datos duplicados antes de escribirlos en un repositorio de backups. Esta técnica requiere menos espacio de almacenamiento en un repositorio de backups, ya que elimina las redundancias del flujo de datos de backup, pero prolonga el tiempo de backup, ya que la deduplicación en línea se produce durante el job de backup.
- La deduplicación post-procesamiento procesa los datos después de haberlos escrito en el repositorio de backups. Obviamente, este enfoque requiere más espacio libre en el repositorio, pero los backups se ejecutan más rápido y todas las operaciones necesarias se realizan a posteriori. La deduplicación postprocesamiento también se denomina deduplicación asíncrona.
Cómo se realiza la deduplicación de datos
Los métodos más comunes para identificar duplicados son los basados en hash y los basados en hash modificado.
- Con el método basado en hash, el software de deduplicación divide los datos en bloques de longitud fija o variable y calcula un hash para cada uno de ellos utilizando algoritmos criptográficos como MD5, SHA-1 o SHA-256. Cada uno de estos métodos produce una huella digital única de los bloques de datos, por lo que los bloques con hashes similares se consideran idénticos. El inconveniente de este método es que puede requerir importantes recursos informáticos, especialmente en el caso de backups de gran tamaño.
- El método basado en hash modificado utiliza algoritmos de generación de hash más sencillos, como CRC, que sólo producen 16 bits (frente a los 256 bits de SHA-256). A continuación, si los bloques tienen hashes similares, se comparan byte a byte. Si son completamente similares, se considera que los bloques son idénticos. Este método es un poco más lento que el basado en hash, pero requiere menos recursos informáticos.
Elegir un software de deduplicación de backups
La deduplicación de backups es uno de los usos prácticos más populares de la deduplicación. Aun así, es necesario contar con la solución de software y el hardware de almacenamiento adecuados para aplicar esta tecnología de reducción de datos.
NAKIVO Backup & Replication es una solución de backup compatible con el uso de la deduplicación global de post-procesamiento de destino con detección de duplicados basada en hash modificado. También puede aprovechar las ventajas de la deduplicación en origen integrando un appliance de deduplicación como DELL EMC Data Domain con DD Boost, NEC HYDRAstor y HP StoreOnce con compatibilidad con Catalyst con la solución NAKIVO.



