¿Qué es una conmutación por recuperación? Casos prácticos de clustering y replicación
La disponibilidad de las máquinas virtuales es esencial para garantizar la continuidad del negocio. Cuando los servicios que se ejecutan en máquinas virtuales críticas para la empresa dejan de estar disponibles, las empresas pueden perder dinero y la confianza de sus clientes. Para restaurar la disponibilidad de la máquina virtual inmediatamente después de un fallo, debe utilizar las técnicas de conmutación por recuperación adecuadas.
La conmutación por error a una réplica de máquina virtual puede formar parte de la recuperación ante desastres para restaurar los datos y las operaciones con una interrupción mínima de los flujos de trabajo habituales. El proceso de conmutación por recuperación de máquinas virtuales debe describirse en el plan de continuidad de negocio y recuperación ante desastres (BCDR) de una organización. Veamos con más detalle los tipos de conmutación por recuperación de máquinas virtuales y los casos de uso práctico.

¿Qué es una conmutación por recuperación?
La conmutación por recuperación es el proceso de reanudación de una máquina virtual (VM) en un sistema secundario (y a veces en una ubicación secundaria) tras un fallo del sistema primario. El sistema secundario contiene todos los datos necesarios para mantener las operaciones de la empresa. En este contexto, un sistema puede ser un servidor, una base de datos, una máquina virtual, etc.
En los entornos virtuales, existen dos métodos habituales de conmutación por recuperación:
- El uso de una réplica de máquina virtual (normalmente ubicada en otro servidor de virtualización) se utiliza para realizar la conmutación por error si falla una máquina virtual principal.
- Uso de un clúster de conmutación por recuperación (no requiere replicación)
La conmutación por recuperación requiere menos tiempo para restaurar las cargas de trabajo en comparación con la recuperación a partir de un backup y, como resultado, se puede alcanzar un objetivo de tiempo de recuperación (RTO) más bajo. Sin embargo, el uso de la replicación de máquinas virtuales o la agrupación en clústeres no elimina la necesidad de hacer backups de las máquinas virtuales. Hacer backups (normalmente comprimidos) es útil cuando se necesita recuperar datos del antiguo punto de recuperación.
Repasemos la terminología básica de conmutación por error de máquinas virtuales para la recuperación ante desastres basada en la replicación.
Glosario de conmutación por recuperación
- Fallo: Cualquier problema con el hardware o el software como resultado de una caída del sistema, corte de energía, problemas de red, ataque de ransomware, etc., que deja fuera de servicio un sistema.
- Sistema primario: El sistema que ejecuta operaciones en vivo en el entorno de producción.
- Sistema secundario: El sistema redundante de reserva, que se actualiza periódicamente con copias del sistema primario. El sistema secundario puede instalarse localmente o en una ubicación remota.
- Replicación: El proceso esencial para preparar la conmutación por recuperación de máquinas virtuales. La replicación crea una copia exacta, es decir, una réplica, de la máquina virtual primaria para un momento determinado.
- VM conmutación por error: La conmutación por error es el proceso de volver al sistema primario desde la réplica VM una vez resuelta la incidencia.
Tipos de conmutación por recuperación
Existen tres tipos de conmutación por recuperación:
- Una conmutación por recuperación planificada se utiliza para migraciones programadas de cargas de trabajo de un sistema/sitio a otro. Los casos de uso práctico incluyen la realización de tareas de mantenimiento en el sistema primario, los trabajos eléctricos realizados en el centro de producción y los escenarios de catástrofe previstos. Por ejemplo, una alerta meteorológica sobre un tornado puede requerir una conmutación por error planificada para garantizar la disponibilidad.
- Una conmutación por recuperación no planificada es la que se realiza cuando se produce un fallo inesperado que provoca que una máquina virtual crítica o todo el sitio primario quede fuera de línea. El fallo puede deberse a una catástrofe natural, un accidente (corte de electricidad), un ataque de malware o cualquier otro incidente. Para una conmutación por recuperación no planificada, los hosts y las réplicas deben estar preparados de antemano.
- Una conmutación por recuperación de prueba, como su nombre indica, se utiliza con fines de prueba. Los escenarios de prueba pueden incluir el ensayo de escenarios de conmutación por recuperación no planificados para garantizar que
Secuencia de conmutación por recuperación
Durante una conmutación por recuperación de una máquina virtual, la secuencia de acciones de conmutación por recuperación y el orden de inicio de la máquina virtual son esenciales para garantizar la reanudación satisfactoria de los flujos de trabajo. Deben definirse en la fase de desarrollo del plan de recuperación ante desastres de su organización. La secuencia debe capturar las dependencias entre los diferentes servicios que se ejecutan en diferentes máquinas virtuales.
Por ejemplo, la autenticación para algunos servicios y aplicaciones que se ejecutan en máquinas virtuales puede utilizar Active Directory, que se ejecuta en otra máquina virtual. Un servidor de base de datos podría estar ejecutándose en la primera máquina virtual, un servidor de aplicaciones en la segunda y el servidor web en la tercera.
Primero debe iniciarse la máquina virtual con el servidor de Active Directory. A continuación, se pueden iniciar las máquinas virtuales con servicios que utilizan Active Directory para la autenticación. La VM con el servidor de base de datos debe iniciarse antes que la VM con el servidor de aplicaciones, porque el servidor de aplicaciones se conecta a la base de datos. Una vez iniciadas las máquinas virtuales con el servidor de bases de datos y el servidor de aplicaciones, se puede iniciar la máquina virtual con el servidor web.
Principales soluciones de conmutación por recuperación
Las principales soluciones utilizadas en entornos virtuales son:
- conmutación por recuperación (failover clustering)
- conmutación por recuperación mediante réplicas de máquinas virtuales
Analicemos cada una de ellas.
Solución 1. Conmutación por recuperación en clústeres
Un clúster de conmutación por recuperación es un grupo de al menos dos servidores o nodos configurados para hacerse cargo de las cargas de trabajo cuando un nodo está caído o no disponible. La agrupación en clústeres es una solución automatizada de clase empresarial que puede utilizarse para las máquinas virtuales más importantes y críticas para el negocio. Microsoft Hyper-V ofrece un clúster de conmutación por recuperación formado por varios hosts Hyper-V. El equivalente de VMware es un clúster de alta disponibilidad, formado por hosts ESXi.
En el primer diagrama siguiente, puede ver un clúster en el que ambos hosts (también llamados nodos) funcionan correctamente. Las máquinas virtuales se ejecutan en hosts y los archivos de las máquinas virtuales se encuentran en un almacenamiento compartido al que pueden acceder ambos hosts.
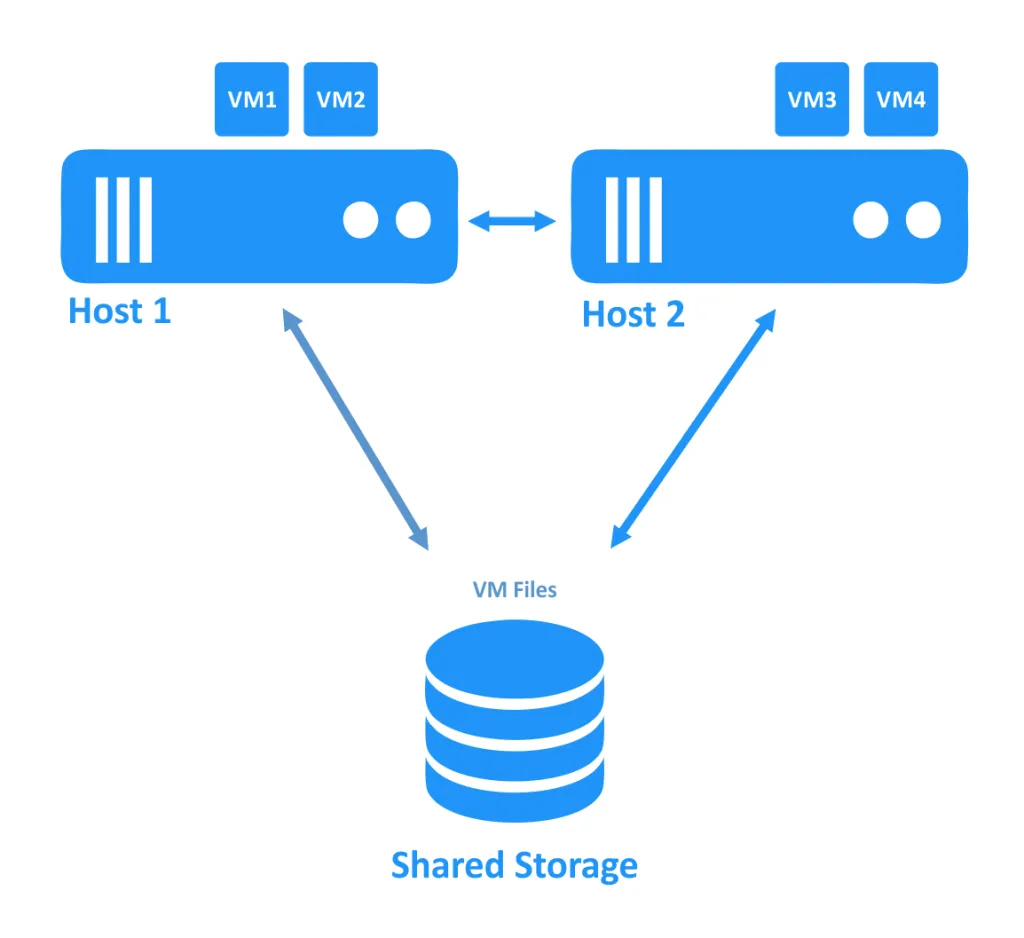
Cuando uno de los hosts se cae, la propiedad de la conexión a la máquina virtual (que se estaba ejecutando en el nodo desconectado) se transfiere a otro nodo que sigue conectado. Este es el proceso de conmutación por recuperación. Puede ser necesario reiniciar una máquina virtual de alta disponibilidad.
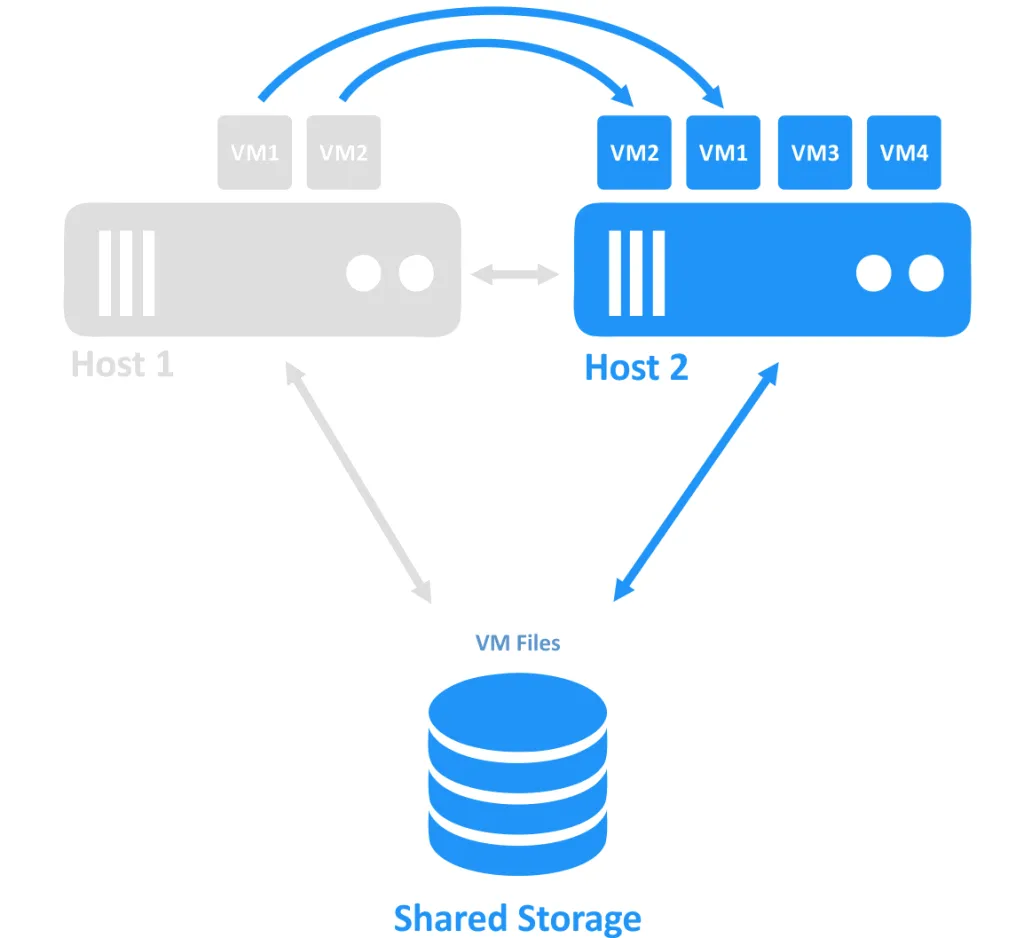
Requisitos de la conmutación por recuperación en clústeres
Para crear un clúster de conmutación por recuperación deben cumplirse los siguientes requisitos:
- Almacenamiento compartido conectado a los hosts con una red dedicada de alta velocidad y baja latencia. Se debe utilizar un sistema de archivos en clúster para garantizar que varios hosts puedan acceder simultáneamente a los datos ubicados en el almacenamiento.
- Los hosts en los que se ejecutan las máquinas virtuales deben tener el mismo hardware o, al menos, hardware de la misma familia. Los procesadores deben admitir los mismos conjuntos de instrucciones para garantizar la compatibilidad con las máquinas virtuales para que se ejecuten correctamente después de la migración de un host a otro durante la conmutación por error.
- Una red redundante de alta velocidad y baja latencia. Debe haber varias redes de clúster separadas, es decir, un clúster debe tener redes diferentes para el almacenamiento, la gestión, la migración de máquinas virtuales, la conexión de hosts entre sí, etc.
Casos prácticos
Los clústeres de conmutación por recuperación se utilizan para recuperar máquinas virtuales en caso de fallo del servidor, proporcionando alta disponibilidad para máquinas virtuales críticas. Si uno de los hosts (denominados nodos) de un clúster falla, las máquinas virtuales que se estaban ejecutando en el host que ha fallado migran (conmutación por error) a otros hosts sanos. Dependiendo de sus ajustes, las máquinas virtuales sobre las que se produjo el fallo pueden migrarse de nuevo al host en el que se estaban ejecutando antes del incidente una vez que se resuelva el fallo.
Ventajas
Un clúster de conmutación por recuperación tiene ventajas que proporcionan una fuerte protección:
- Un clúster de conmutación por recuperación proporciona conmutación automática de máquinas virtuales. No es necesario iniciar manualmente las máquinas virtuales averiadas en otros hosts.
- Tras la conmutación por recuperación, la pérdida de datos es prácticamente nula. El tiempo de inactividad suele limitarse al que se tarda en cargar la máquina virtual, el sistema operativo y el software que se ejecuta en ella.
- La función de tolerancia a fallos incluida en el clúster de alta disponibilidad de VMware garantiza la conmutación por error de las máquinas virtuales sin tiempo de inactividad ni pérdida de datos.
Desventajas
Un clúster de conmutación por recuperación no protege contra:
- Fallo de software de las máquinas virtuales. Los errores de software o los virus pueden provocar un fallo del sistema en una máquina virtual.
- Eliminación accidental de archivos dentro de la máquina virtual.
- Fallo del almacenamiento compartido. El clúster falla si falla el almacenamiento compartido. El almacenamiento compartido es un componente crucial del clúster; los discos virtuales que pertenecen a las máquinas virtuales dentro de un clúster se almacenan en el almacenamiento compartido.
- Un desastre que hace que todo el sitio físico no esté disponible.
Para obtener más información sobre qué es un clúster de conmutación por recuperación, lea la guía completa sobre clústeres de VMware.
Solución 2. Conmutación por recuperación mediante réplicas de máquinas virtuales
La conmutación por recuperación basada en réplicas de máquinas virtuales puede ser ejecutada por aplicaciones especializadas, que pueden replicar las máquinas virtuales e iniciar las réplicas cuando lo solicite el administrador. Además del software de protección de datos, necesita hosts ESXi o Hyper-V (dependiendo de su entorno) que se hayan preparado de antemano para ejecutar las réplicas de las máquinas virtuales cuando fallen las máquinas virtuales de origen.
En el diagrama siguiente, puedes ver dos hosts conectados entre sí a través de la red. Las máquinas virtuales utilizan los discos de los hosts. Las máquinas virtuales de origen se ejecutan en el primer host, y las réplicas de las máquinas virtuales, que son copias exactas de las máquinas virtuales de origen en un momento determinado, se encuentran en el segundo host en estado apagado.
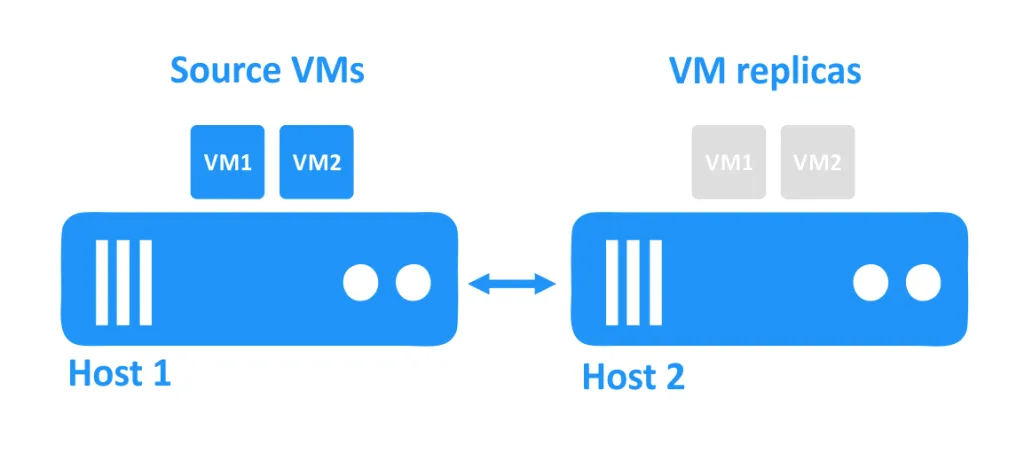
Cuando un host se cae, las máquinas virtuales que se estaban ejecutando en ese host también se vuelven inaccesibles. A continuación, el administrador enciende las réplicas de la máquina virtual que se encuentran en otro host.
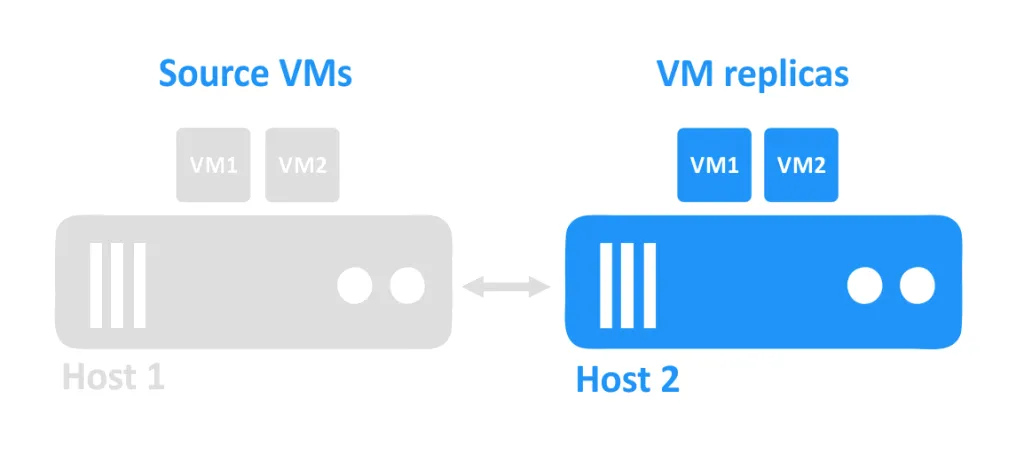
Requisitos de replicación de máquinas virtuales
Los requisitos básicos para la replicación de máquinas virtuales son dos o más hosts y una solución de replicación. Una máquina virtual de origen que se ejecuta en el primer host se replica en el segundo host. La réplica de la máquina virtual se encuentra en el segundo host.
Casos prácticos
La conmutación por recuperación mediante réplicas de máquinas virtuales puede utilizarse cuando se produce un fallo de hardware o software. Los fallos de host ESXi o Hyper-V son un ejemplo de fallo de hardware. Ejemplos de fallos de software pueden ser actualizaciones fallidas, errores de software, ataques de virus o el borrado accidental de archivos por parte de un usuario.
Ventajas
La principal ventaja de la conmutación por recuperación de máquinas virtuales a una réplica es la posibilidad de conmutación por error a un sitio remoto. Cuando se está creando una réplica de una máquina virtual, los datos copiados de una máquina virtual de origen pueden transmitirse a través de una conexión de red (con un ancho de banda limitado) a un sitio remoto. El sitio remoto puede estar situado en una oficina cercana o en la otra punta del mundo. La réplica VM también puede estar ubicada en el sitio de producción primario.
Desventajas
La lista de desventajas de una conmutación por recuperación mediante réplicas de máquinas virtuales:
- Hay un breve periodo de inactividad entre un fallo y el inicio de la réplica en el segundo host.
- La conmutación por recuperación debe iniciarse manualmente.
- Los datos escritos desde la última replicación pueden perderse durante una conmutación por error no planificada. La replicación de máquinas virtuales no suele ser un proceso en tiempo real (síncrono), ya que la replicación síncrona supone una carga importante para los recursos. La replicación suele realizarse a intervalos de tiempo regulares en función de los ajustes elegidos.
- Los ajustes de red de las máquinas virtuales deben modificarse (a menudo) en caso de conmutación por recuperación a otro sitio. Las redes VM del sitio remoto pueden diferir de las redes del sitio primario. Por lo tanto, las direcciones IP también pueden ser diferentes, y deben comprobarse y cambiarse junto con los demás ajustes de red durante la conmutación por recuperación.
Conmutación por recuperación de máquinas virtuales basada en clústeres o en replicación
| Conmutación por recuperación con agrupación en clústeres | Conmutación por recuperación mediante una réplica | |
| Propósito | Alta disponibilidad | Recuperación ante desastres |
| Protección contra | Sólo fallos de hardware | Fallos de hardware y software |
| administración | Lanzamiento automático | Lanzamiento manual |
| Duración del tiempo de inactividad (RTO) | La conmutación por recuperación es más rápida, por lo que el tiempo de inactividad de la máquina virtual es menor (RTO corto). | La conmutación por recuperación lleva más tiempo, por lo que el tiempo de inactividad de las máquinas virtuales es mayor. |
| Requisitos | Más requisitos | Menos requisitos |
| Solución Precio | Las soluciones de agrupación suelen ser más caras | Las soluciones de replicación son más rentables |
| Pérdida de datos (RPO) | Pérdida de datos casi nula (RPO muy bajo) | La pérdida de datos depende de la frecuencia de replicación |
Uso combinado de clusters y réplicas para conmutación por recuperación de máquinas virtuales
Las soluciones de conmutación por error en clúster y réplica a veces se consideran alternativas, pero pueden utilizarse de forma complementaria. Veamos algunos ejemplos de cómo el uso de ambas soluciones de conmutación por recuperación puede ayudar a proteger sus máquinas virtuales contra fallos tanto a nivel de servidor como de sitio.
- Ejemplo 1: Puede replicar las máquinas virtuales que se ejecutan dentro de un clúster a un host en un sitio remoto. Además, puede replicar las máquinas virtuales que se ejecutan en un clúster a otro clúster. Así, si un host falla, el clúster de conmutación por recuperación mantiene esas máquinas virtuales en línea. Si todo el sitio experimenta una interrupción, puede conmutar por error a las réplicas de máquinas virtuales almacenadas en un sitio remoto.
- Ejemplo 2: Un virus daña los archivos de algunas máquinas virtuales. Un clúster de conmutación por recuperación no puede proteger contra este tipo de fallos. Pero si tiene réplicas de VM con múltiples puntos de recuperación, puede restaurar cada VM a un punto de tiempo anterior a que sus archivos fueran dañados o borrados.
Uso de la solución NAKIVO para la conmutación por error automatizada de máquinas virtuales VMware a réplica
NAKIVO Backup & Replication es una solución de copia de seguridad y recuperación ante desastres que puede proteger máquinas virtuales que se ejecutan en un clúster, replicar máquinas virtuales, conmutar por error a réplicas y orquestar secuencias complejas de recuperación ante desastres. Tanto los clusters como los hosts ESXi o Hyper-V independientes son compatibles como puntos de origen y destino para la replicación. La solución rastrea automáticamente el host en el que reside una máquina virtual para poder replicarla. Esto es útil porque las máquinas virtuales pueden migrar de un host a otro dentro de un clúster tras eventos de conmutación por error o eventos de equilibrio de carga (un clúster se suele configurar junto con el equilibrio de carga). Por eso, el software que utilices para replicar una máquina virtual desde un clúster debe ser capaz de rastrear el host en el que reside la máquina virtual.
La solución NAKIVO puede cambiar automáticamente los ajustes de red de la máquina virtual en caso de conmutación por recuperación; sólo tiene que utilizar las funciones de mapeo de la red y Re-IP al configurar un job de replicación o conmutación por recuperación.
Veamos un ejemplo de conmutación por error automatizada de máquinas virtuales (con mapeo de la red y Re-IP) en NAKIVO Backup & Replication. Empezaremos creando una réplica de la máquina virtual.
Configuración de la replicación necesaria para la conmutación por error de máquinas virtuales
En el panel Jobs, haga clic en Create > VMware vSphere replication job si tiene un entorno virtual VMware. Tenga en cuenta que puede crear un job de replicación para una máquina virtual Microsoft Hyper-V o una instancia Amazon EC2 del mismo modo.
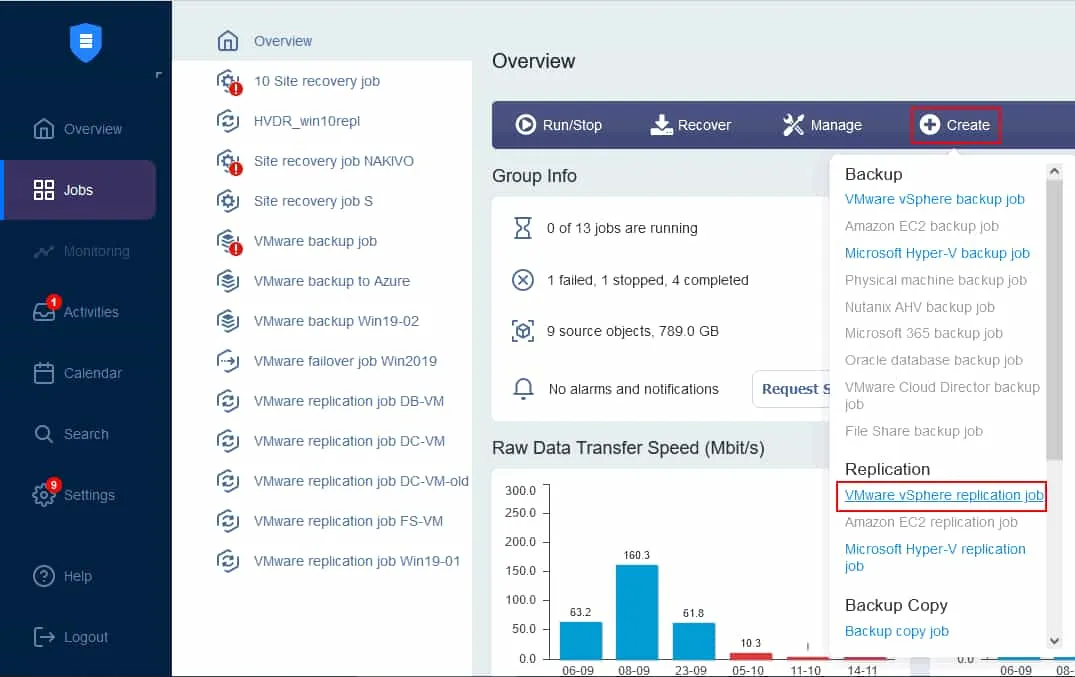
Se inicia el asistente de jobs de replicación.
- Seleccione las máquinas virtuales que desea replicar. En este ejemplo, se replicará la VM Server2019, que ejecuta Windows Server 2019 como sistema operativo invitado. Haga clic en Siguiente.
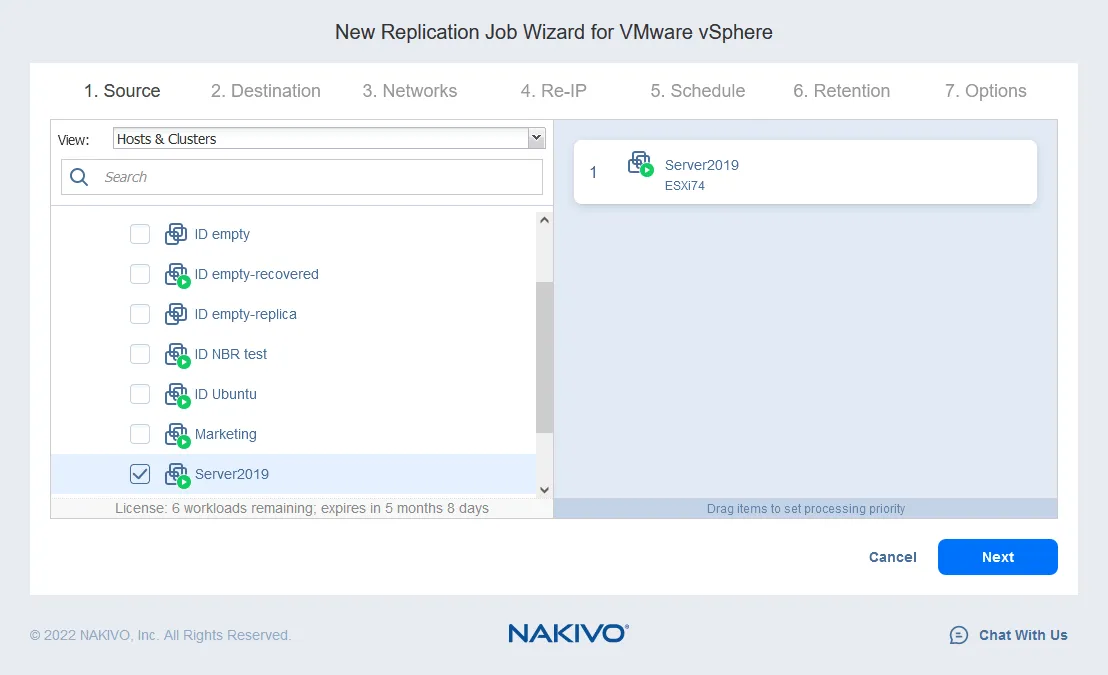
- Seleccione un host de destino para que se ejecute la réplica de la máquina virtual(10.10.10.90 en nuestro caso). Seleccione el almacén de datos montado en el host seleccionado para colocar los archivos de la máquina virtual. Haga clic en Siguiente.
- Puede establecer las opciones de mapeo de la red y Re-IP al configurar un job de replicación o un job de conmutación por error. En este tutorial, el mapeo de la red y Re-IP se configurarán más adelante, cuando se configure el job de conmutación por recuperación. Por lo tanto, puede omitir este paso por el momento y hacer clic en Siguiente.
- La configuración de Re-IP se explicará durante la configuración del job de conmutación por recuperación de máquinas virtuales en este tutorial. Haga clic en Siguiente.
- Selecciona tus ajustes de programación. Haga clic en Siguiente cuando haya terminado.
- Configura los ajustes de retención. Recuerde que en este paso puede configurar la política de retención abuelo-padre-hijo. Haga clic en Siguiente.
- Seleccione las opciones del job de replicación y pulse Finalizar o el botón Finalizar & Ejecutar. Espere mientras se crea la réplica.
Configuración de conmutación por recuperación de máquinas virtuales
Ahora que tiene una réplica de VM creada, puede realizar la conmutación por error de VM a esta réplica.
En la página de inicio del panel de control, haga clic en Recuperar > VMware Recuperación completa (conmutación por error de réplica de VM). Se abre el Asistente para nuevo job de conmutación por recuperación.
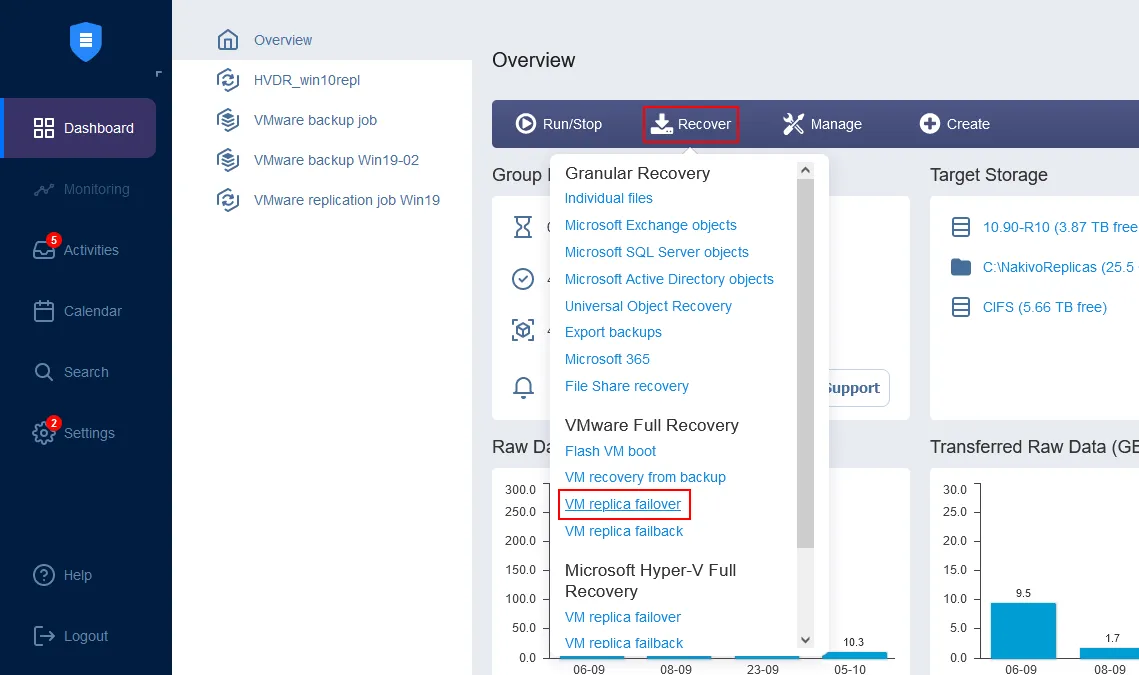
- En el panel izquierdo, seleccione la réplica de la máquina virtual que se utilizará para la conmutación por recuperación. En este tutorial, se selecciona la réplica Server2019 que se acaba de crear. En el panel derecho, seleccione un punto de recuperación. En la solución se selecciona por defecto el último punto de recuperación. Haga clic en Siguiente.
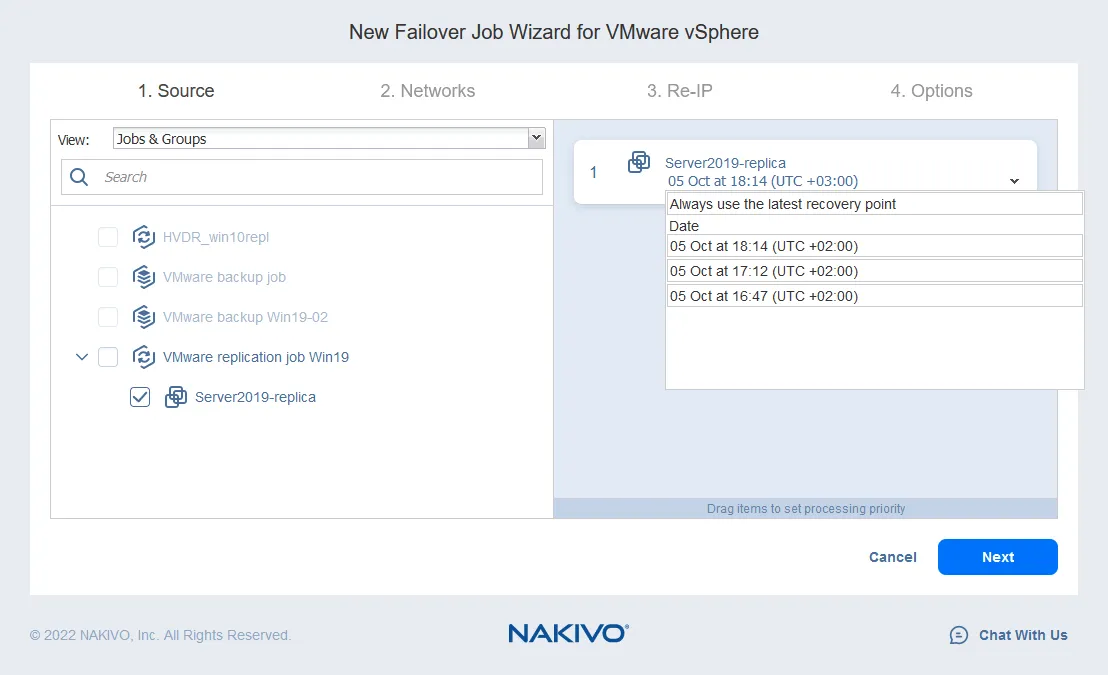
- El mapeo de la red le ayuda a cambiar la red a la que está conectada la máquina virtual. Es probable que los hosts ESXi de origen y destino tengan ajustes de conmutador virtual diferentes. Dado que una réplica de VM es una copia exacta de la VM de origen, las redes virtuales a las que está conectada la VM de origen se conservan en la réplica de VM.
Generalmente, debe comprobar los ajustes de red de una réplica VM y cambiar manualmente la red. NAKIVO Backup & Replication puede asignar automáticamente la red de origen a una red de destino. Sólo tiene que configurar el mapeo de la red al configurar el job de replicación o conmutación por recuperación.
- Para activar el mapeo de la red, seleccione la casilla. Si ha creado previamente una regla de mapeo de la red, puede hacer clic en Añadir mapeo existente. Si no hay reglas de mapeo de la red, haga clic en Crear nuevo mapeo.
-
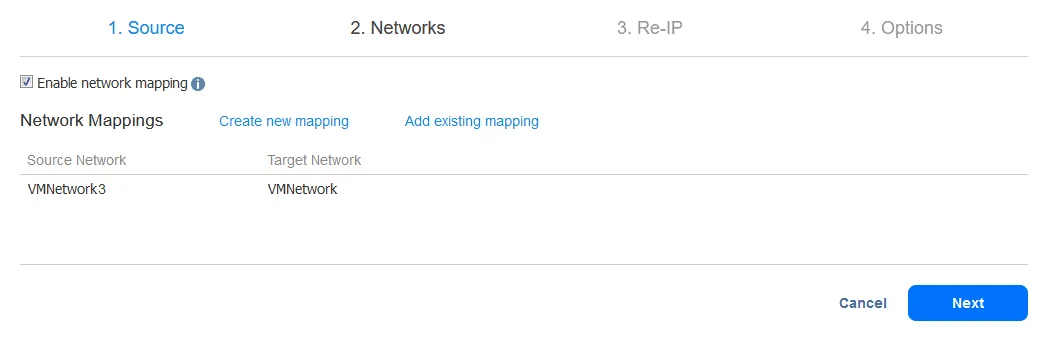
Para crear una nueva regla de mapeo de la red, seleccione la red de origen y la red de destino. La red de origen es la red a la que está conectada la máquina virtual de origen. La red de destino (target) es la red a la que debe conectarse la réplica VM.
Nota: El nombre de red de la VM no es el mismo que la dirección IP o la dirección de red.
Haga clic en Guardar para guardar la regla de mapeo de la red y, a continuación, en Siguiente para continuar con la configuración.
- Para activar el mapeo de la red, seleccione la casilla. Si ha creado previamente una regla de mapeo de la red, puede hacer clic en Añadir mapeo existente. Si no hay reglas de mapeo de la red, haga clic en Crear nuevo mapeo.
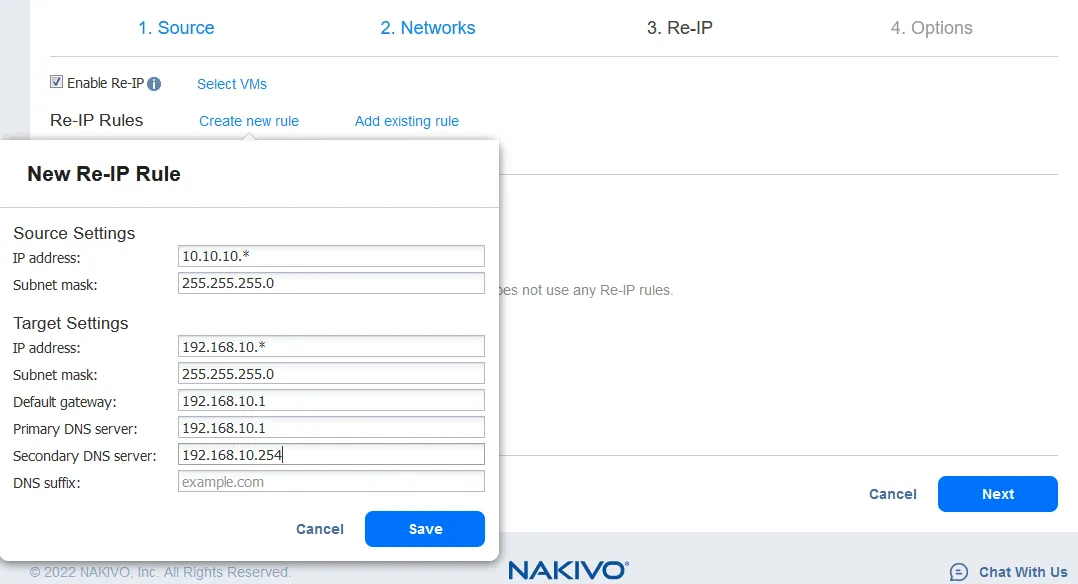
- La función Re-IP permite cambiar los ajustes IP de la réplica VM. Puede utilizarse para direcciones IP estáticas.Seleccione la casilla de verificación Activar Re-IP si desea activar esta opción y, a continuación, cree una regla Re-IP o añada una regla existente. Haga clic en Crear nueva regla si no hay reglas creadas anteriormente. Aparece un menú emergente.
- Los ajustes de la máquina virtual de origen son la dirección IP y la máscara de red que hay que cambiar.
-
Los ajustes de destino son los ajustes que se aplicarán a la réplica de la máquina virtual cuando se produzca la conmutación por recuperación.En este ejemplo, el carácter [*] cubre el último octeto. El [*] significa cualquier número del 1 al 254. Si las direcciones IP de origen son, por ejemplo, 10.10.10.1, 10.10.10.96 y 10.10.10.222, las direcciones de destino serían 192.168.10.1, 192.168.10.96 y 192.168.10.222 respectivamente. Se conserva el último octeto de la dirección IP.
Haga clic en Guardar para guardar la regla Re-IP y continuar.
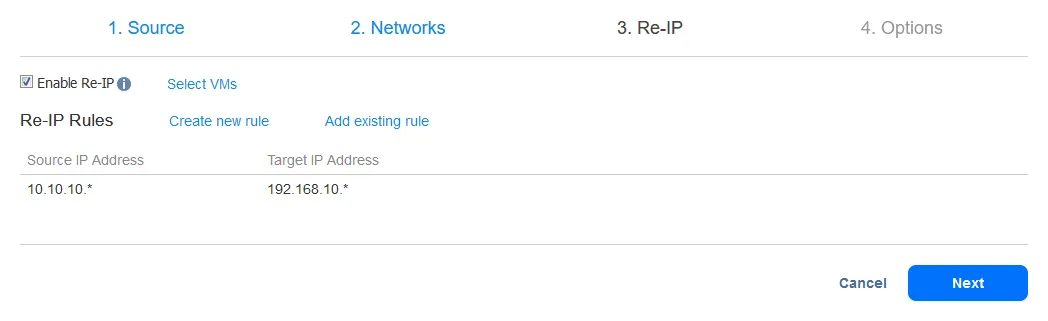
Después de añadir la regla Re-IP, su pantalla debería tener este aspecto:
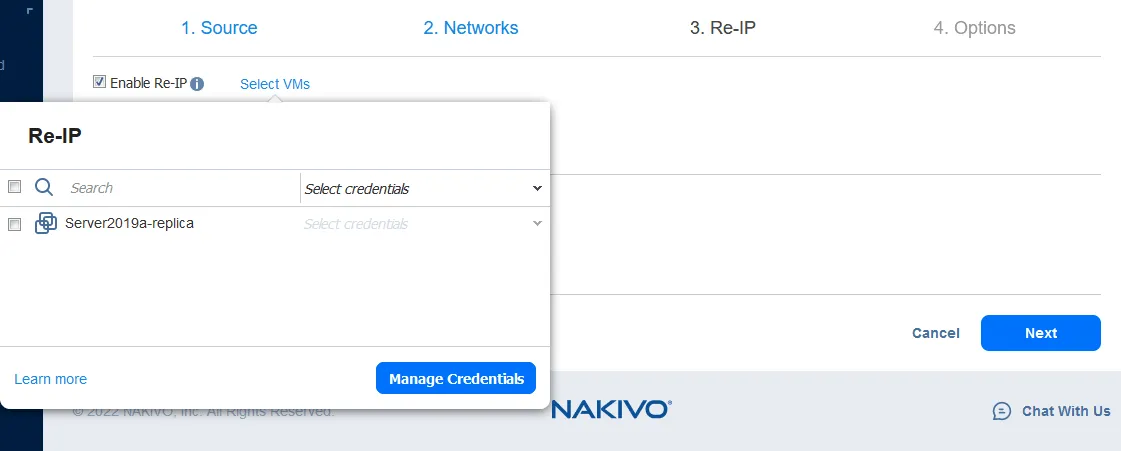
Ahora seleccione las máquinas virtuales a las que se aplicarán las reglas Re-IP. El job de conmutación por recuperación de este ejemplo contiene sólo una réplica de VM, así que seleccione la casilla de verificación una.
A continuación, seleccione las credenciales para cada máquina virtual. Haga clic en Gestionar credenciales > Añadir credenciales para añadir nuevas credenciales. Las credenciales añadidas pueden seleccionarse en la lista desplegable.
Nota: Las credenciales son necesarias para que NAKIVO Backup & Replication acceda a los ajustes de red del sistema operativo dentro de la máquina virtual y aplique el script que cambia dichos ajustes. VMware Tools debe instalarse en las máquinas virtuales VMware vSphere, y Hyper-V Integration Services debe instalarse en las máquinas virtuales Microsoft Hyper-V.
Cuando haya configurado todos estos ajustes, haga clic en Siguiente.
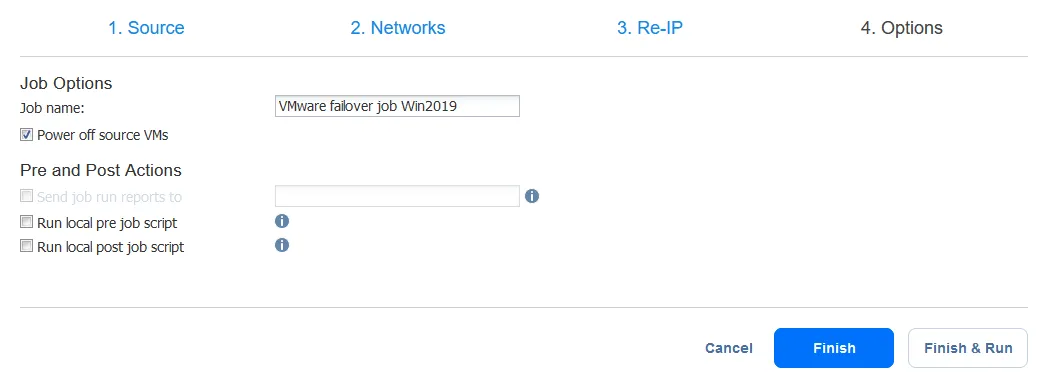
- Ahora, configure las opciones del job de conmutación por recuperación de la máquina virtual. Puede seleccionar la casilla Apagar las máquinas virtuales de origen. Puede ser útil para evitar un conflicto de direcciones IP si las máquinas virtuales de origen y de réplica utilizan la misma red o tienen las mismas direcciones IP. Después de configurar todas las opciones, haga clic en Finalizar & Ejecutar.
Espere hasta que el job de conmutación por recuperación de la VM se complete.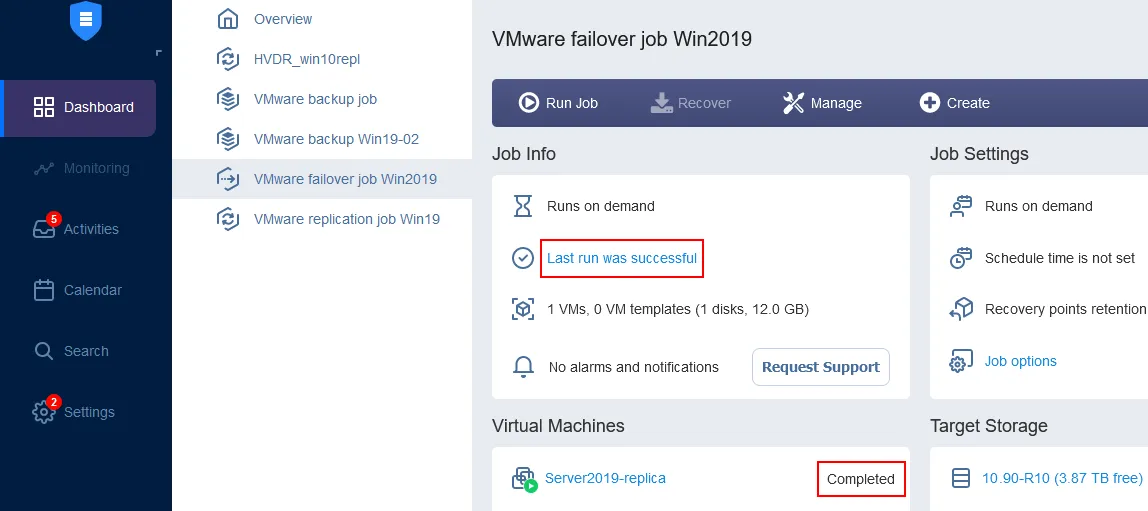
Ahora puede asegurarse de que la réplica de la máquina virtual se está ejecutando. Vaya a Configuración > Inventario y haga clic en el botón Actualizar todo. Después de actualizar, puede ver que la máquina virtual Server2019-replica ya se está ejecutando en el host ESXi de destino. También puede gestionar las credenciales, las reglas de mapeo de la red y las reglas Re-IP desde esta página (la página de Inventario ).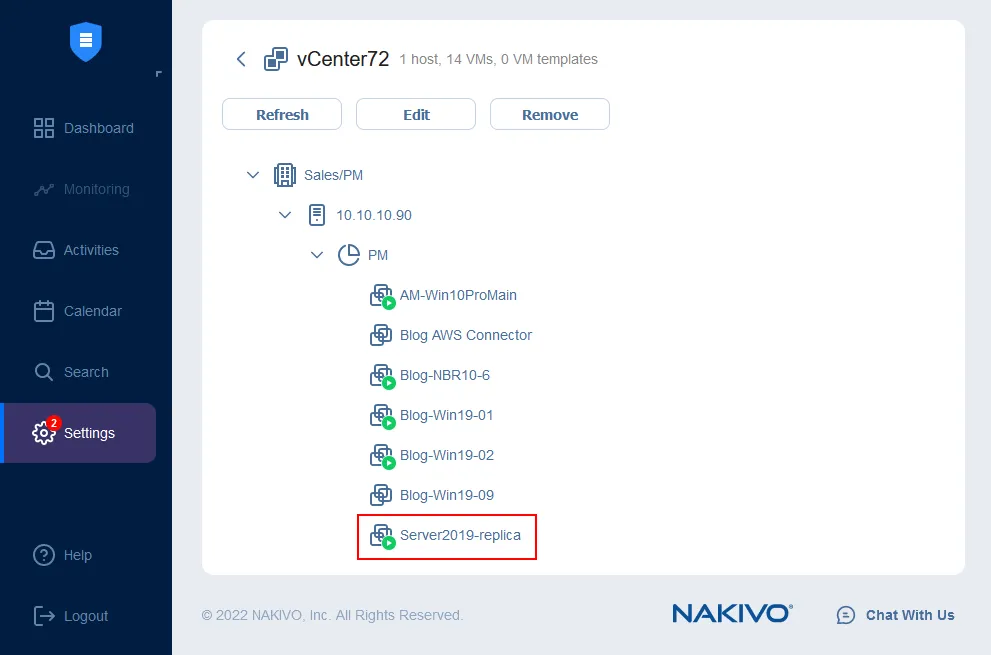
Conclusión
La conmutación por recuperación de máquinas virtuales es útil para escenarios de recuperación ante desastres con muchas máquinas virtuales o para recuperar incluso una sola máquina virtual con el fin de garantizar la continuidad operativa y una alta disponibilidad. Sin embargo, es importante entender que cualquier plan de recuperación ante desastres debe ir acompañado de una sólida estrategia de backups para una protección de datos más fiable y eficaz.
Considere la posibilidad de utilizar NAKIVO Backup & Replication, una solución de protección de máquinas virtuales rápida, fiable y asequible, para proteger las máquinas virtuales utilizando el método de hacer backup de backup a replica. La solución también permite hacer backups y recuperaciones granulares para entornos virtuales, físicos, en la nube y SaaS desde una interfaz web centralizada.



