Cómo Configurar HA en VMware vSphere
Cuando se tienen máquinas virtuales críticas y servicios críticos corriendo en ellas, su disponibilidad debe ser asegurada durante los tiempos de operación de su organización. Una de las formas de lograr una alta disponibilidad es utilizar un clúster para garantizar el funcionamiento continuo de servicios y aplicaciones.
La plataforma de virtualización VMware vSphere permite utilizar un clúster para ejecutar máquinas virtuales (VM) y utilizar vSphere High Availability (HA). Esta entrada de blog explica la configuración de VMware vSphere HA para familiarizarse con los parámetros a configurar.

¿Qué es HA en VMware vSphere?
VMware High Availability (HA) es una función que proporciona una disponibilidad óptima para las máquinas virtuales vSphere, incluidas las aplicaciones y los servicios que se ejecutan en las máquinas virtuales, para minimizar el tiempo de inactividad en caso de fallos. La alta disponibilidad (HA), o la capacidad de un entorno virtual para soportar fallos de host, es una de las razones importantes por las que elegiría implementar VMware vCenter y un clúster en lugar de un host VMware ESXi independiente.
Cuando se ejecuta HA en un clúster VMware, se instala un agente en cada host que participa en el clúster. Cada agente de host se comunica con el otro y supervisa la accesibilidad de los hosts del clúster mediante heartbeats. Si transcurre un intervalo de 15 segundos sin que se reciban latidos de un host concreto y los pings al host también fallan, el host se declara fallido. Las máquinas virtuales que se ejecutan en los recursos de computación/memoria de ese host fallido se transfieren a un host sano y se reinician en ese host.
La HA en vSphere puede supervisar el estado del hardware de los hosts para retirar de forma proactiva las máquinas virtuales de los hosts con problemas de hardware. También hay prioridades de reinicio y orquestación incorporadas en HA y, como resultado, las máquinas virtuales designadas se ponen en línea antes que otras en caso de conmutación por error. Estas funciones están disponibles en las versiones VMware vSphere 6.7 y vSphere 7.
Requisitos del clúster VMware
Hay algunos requisitos de VMware para crear un clúster VMware con HA activado. Entre los requisitos figuran:
- Los hosts del clúster de HA deben tener licencia para vSphere HA. Debe aplicarse VMware vSphere Standard o Enterprise Plus, incluidas las licencias de vCenter Standard.
- Se necesitan dos hosts para activar la HA. Se recomiendan tres o más anfitriones.
- Las direcciones IP estáticas configuradas en cada host son las prácticas recomendadas.
- Se necesita al menos una red de gestión común a todos los hosts.
- Para que las máquinas virtuales se ejecuten en todos los hosts en caso de que se trasladen a diferentes hosts del clúster, los hosts deben tener configuradas las mismas redes y almacenes de datos.
- Se requiere almacenamiento compartido para HA.
- VMware Tools debe ejecutarse en las máquinas virtuales que se supervisan en HA.
Configuración de VMware HA paso a paso
Puede activar VMware HA mientras crea un clúster o cuando ya lo haya creado. En este tutorial de configuración de vSphere HA, nos centramos en configurar la Alta Disponibilidad y tenemos un cluster ya creado. Utilizamos VMware vSphere 7 para explicar paso a paso la configuración de VMware HA.
Cómo activar HA en VMware vSphere
Para habilitar HA en VMware vSphere en un clúster existente, haga lo siguiente:
- Abra VMware vSphere Client en su navegador web.
- Vaya a Hosts y clusters y navegue hasta su cluster.
- Haga clic con el botón derecho del ratón en el nombre del clúster en el panel Navegador.
- Haga clic en Ajustes en el menú contextual.
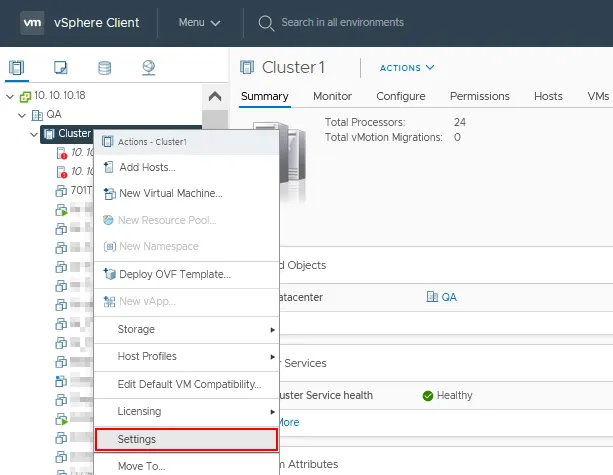
- Seleccione vSphere Availability en la sección Servicios de la página Configurar para su clúster.
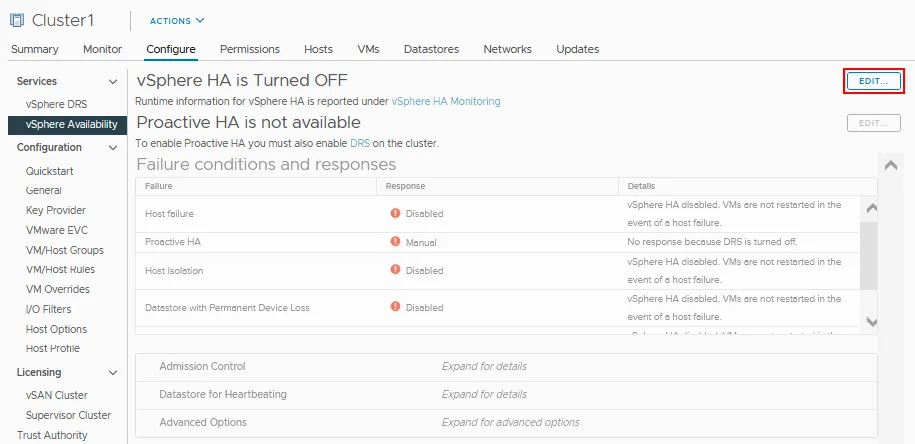
- Haga clic en Editar cerca de vSphere HA que está desactivado en nuestro caso.
- Haga clic en el conmutador vSphere HA para activar la Alta Disponibilidad.
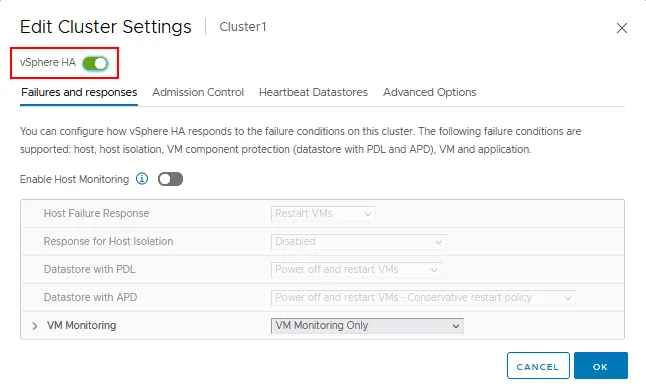
Hay cuatro pestañas con ajustes de vSphere HA:
- Fallos y respuestas
- Control de admisión
- Almacenes de datos Heartbeat
- Opciones avanzadas
Veamos la configuración de vSphere HA que puede realizar editando los ajustes de estas pestañas.
Ficha Fallos y respuestas
La pestaña Fallos y respuestas se utiliza para personalizar el comportamiento de un clúster de HA y establecer qué hacer con las máquinas virtuales en diferentes situaciones.
Activar supervisión de host. Active esta opción para permitir que los hosts ESXi intercambien latidos en el clúster. Un cluster VMware vSphere HA utiliza heartbeats para detectar cuando algún componente del cluster no está disponible. Desactive esta opción cuando realice el mantenimiento de la red para evitar migraciones de máquinas virtuales y conmutaciones por error no deseadas.
Revisemos todos los ajustes de la pestaña Fallos y respuestas.
Respuesta al fallo del host
- Respuesta ante fallos. Utilice estos ajustes para establecer cómo responde un clúster de HA a las condiciones de fallo en este clúster. Hay dos modos disponibles:
- Desactivado: la supervisión del host ESXi está desactivada.
- Reiniciar máquinas vir tuales – Las máquinas virtuales se reinician en el orden determinado en caso de fallo del host.
- Prioridad de reinicio de la máquina virtual por defecto. Esta configuración se utiliza para determinar qué grupo de máquinas virtuales debe reiniciarse en primer lugar. Hay cinco valores: Mínimo, Bajo, Medio, Alto y Máximo. Las máquinas virtuales se reinician por orden de prioridad, un grupo cada vez.
- Condición de reinicio de la dependencia de la máquina virtual. Seleccione una condición que, cuando se cumpla, un clúster detecte que las máquinas virtuales se han reiniciado correctamente y se pueda reiniciar el siguiente lote de máquinas virtuales. Hay cuatro condiciones disponibles:
- Recursos asignados
- Encendido
- Invitado Latidos detectados
- App Latidos detectados
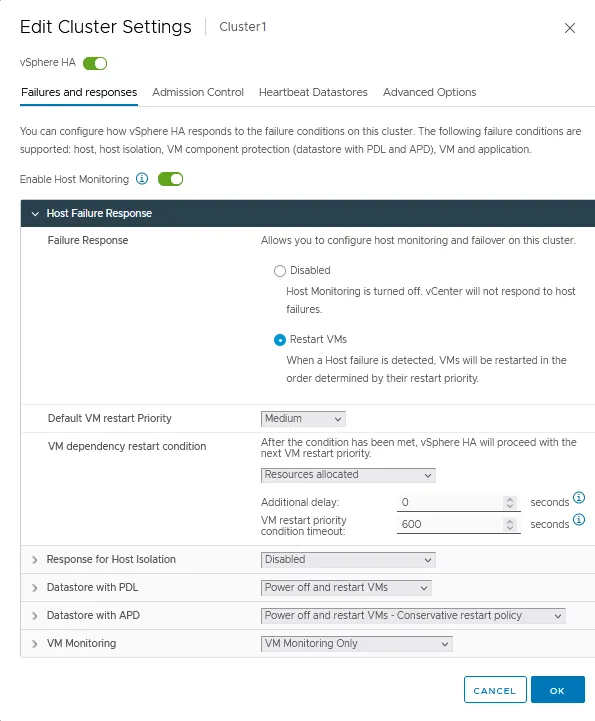
Respuesta para el aislamiento del huésped
La opción Respuesta de aislamiento del host permite configurar el comportamiento de un clúster de HA cuando un host ESXi sigue funcionando pero pierde las conexiones de red de gestión:
- Discapacitados
- Apagar y reiniciar máquinas virtuales
- Apagar y reiniciar máquinas virtuales

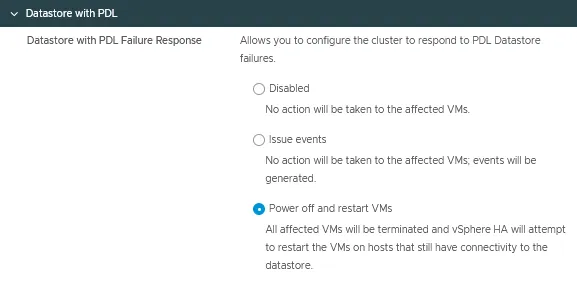
Almacén de datos con PDL
La respuesta a fallos del almacén de datos con pérdida permanente de dispositivos (PDL) puede configurarse para detectar la inaccesibilidad del almacén de datos por parte de un host ESXi e iniciar una conmutación por error automatizada de las máquinas virtuales afectadas.
Existen tres modos para esta opción de configuración de vSphere HA:
- Discapacitados
- Eventos
- Apagar y reiniciar máquinas virtuales
Almacén de datos con APD
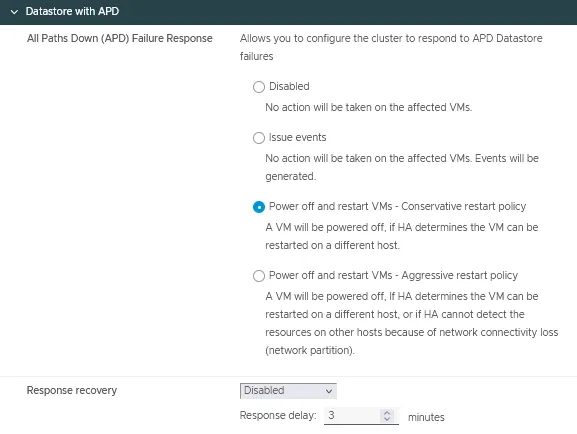
- All Paths Down (APD) Failure Response es la condición que permite a un cluster responder cuando todos los caminos están caídos, y no hay indicación de si se trata de una pérdida temporal o permanente del dispositivo.
Hay cuatro opciones disponibles para este ajuste:- Discapacitados
- Eventos
- Apagado y reinicio de máquinas virtuales – Política de reinicio conservadora
- Apagado y reinicio de máquinas virtuales – Política de reinicio agresiva
- La recuperación de la respuesta tiene dos opciones:
- Discapacitados
- Reiniciar máquinas virtuales
Puede ajustar el retardo de respuesta en minutos.
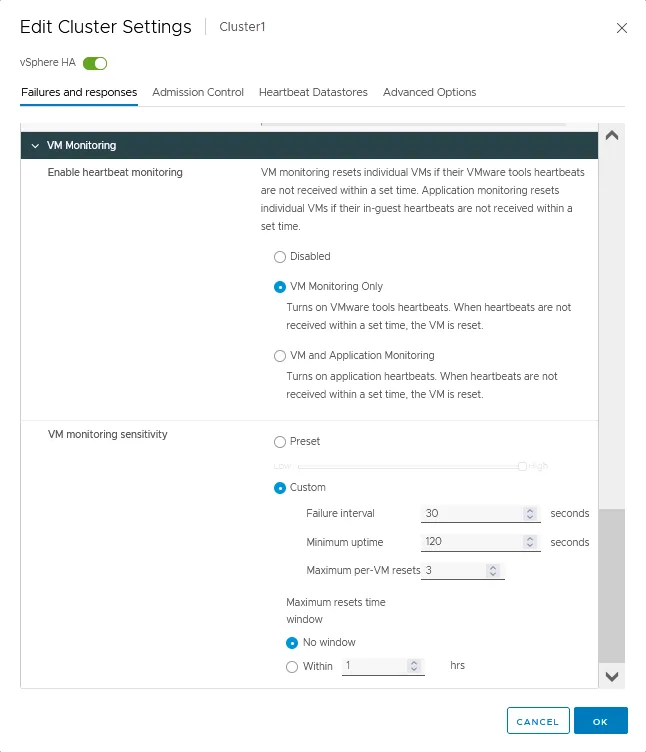
Supervisión de máquinas virtuales
- Habilite la supervisión de latidos para máquinas virtuales mediante las herramientas VMware Tools que se ejecutan en ellas. También puede configurar la supervisión de aplicaciones mediante estas funciones. Si los latidos de la máquina virtual no se reciben a tiempo, se inicia el reinicio de la máquina virtual. Existen tres opciones para este ajuste en la configuración del clúster VMware:
- Discapacitados
- Sólo supervisión de máquinas virtuales
- Supervisión de máquinas virtuales y aplicaciones
- La sensibilidad de supervisión de máquinas virtuales se utiliza para establecer el tiempo tras el cual una máquina virtual se clasifica como no disponible y un clúster de HA puede iniciar el reinicio de la máquina virtual.
- Preestablecido. Puedes mover el conmutador del valor bajo al alto.
- A medida. Establezca parámetros de sensibilidad personalizados, incluidos el intervalo de fallo, el tiempo máximo de actividad y los reinicios máximos por VM. La ventana de tiempo máximo de reinicio puede ajustarse a un valor personalizado en horas.
Nota: También puede utilizar una solución de supervisión de máquinas virtuales para detectar fallos y problemas en máquinas virtuales que no estén en un clúster.
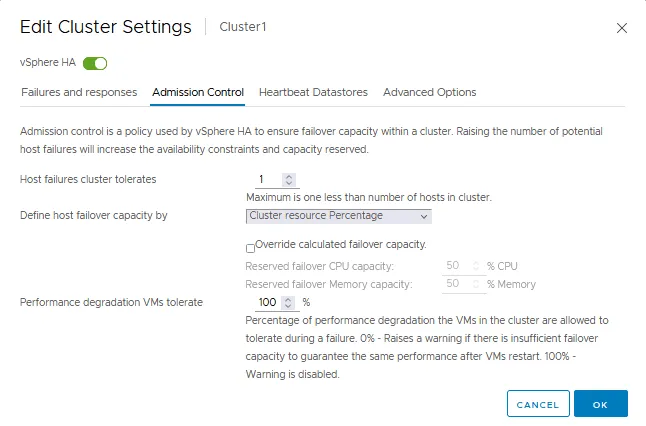
Pestaña Control de admisión
El control de admisión es una política utilizada para garantizar la reserva de recursos suficientes para las máquinas virtuales en ejecución en caso de conmutación por error en un clúster de HA de VMware. Los ajustes de control de admisión garantizan la capacidad de conmutación por recuperación. Si una acción infringe los ajustes de control de admisión, la acción no está permitida. Estas acciones no permitidas pueden ser encender una máquina virtual, migrar una máquina virtual y aumentar los ajustes de CPU y memoria de una máquina virtual.
- El control de admisión define cuántos fallos puede tolerar un clúster de HA y aún así hacer posible la conmutación por error de las máquinas virtuales (una garantía de conmutación por error de las máquinas virtuales).
- Puede definir la capacidad de conmutación por recuperación del host mediante:
- Porcentaje de recursos del clúster
- Hosts dedicados de conmutación por recuperación
- Política de franjas horarias
Si desactiva el control de admisión, no podrá garantizar que se reinicie el número esperado de máquinas virtuales en un clúster de HA en caso de conmutación por error.
- Degradación del rendimiento que toleran las máquinas virtuales es el ajuste que define el porcentaje de degradación del rendimiento que puede tolerar su clúster. 0% significa que debe garantizarse el mismo nivel de rendimiento de la máquina virtual tras la conmutación por error/reinicio de la máquina virtual. De lo contrario, se muestra la advertencia. 100% significa que la advertencia está desactivada y un clúster intenta reiniciar una máquina virtual de todos modos.
Pestaña Almacenes de datos de Heartbeat
Los almacenes de datos Heartbeat proporcionan una forma secundaria de supervisar la disponibilidad de los hosts ESXi mediante el uso de almacenes de datos si la conexión de red a los hosts ESXi no está disponible y ha fallado una red de gestión. Este enfoque permite a vSphere distinguir entre el fallo del host y la indisponibilidad del host a través de la red. Utilice almacenes de datos de heartbeat en la configuración de HA de VMware para supervisar los hosts cuando falla una red de HA.
La política de selección del almacén de datos de Heartbeat tiene tres opciones:
- Seleccionar automáticamente almacenes de datos accesibles desde los hosts
- Utilizar almacenes de datos sólo de la lista especificada
- Utiliza almacenes de datos de la lista especificada y complementa automáticamente si es necesario

La pestaña Opciones avanzadas
La pestaña Opciones avanzadas permite configurar vSphere HA introduciendo manualmente una opción y un valor en cada cadena. Puede utilizar las opciones avanzadas cuando no pueda ajustar un clúster de HA en los ajustes estándar que hemos explicado antes, que están disponibles en la GUI de VMware vSphere Client.
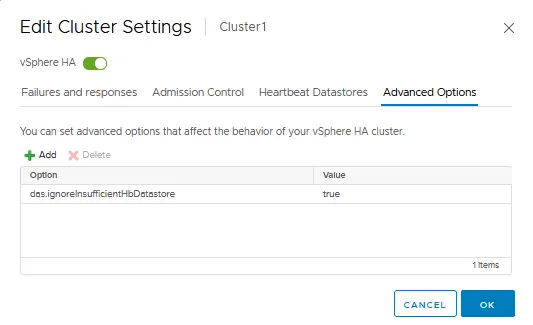
Al igual que con VMware Distributed Resource Scheduler (DRS), una vez que hacemos clic en Aceptar, el clúster de VMware se vuelve a configurar para los ajustes de HA que se configuraron anteriormente.
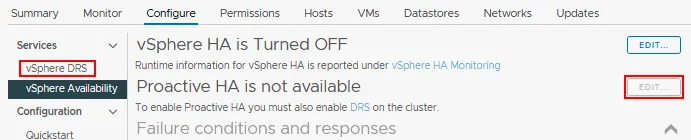
VMware vSphere HA proactiva
La HA proactiva es una función que hace que un clúster reaccione ante un problema antes de que se produzca un fallo en todos los hosts ESXi y las máquinas virtuales que residen en ese host. Los problemas pueden producirse con distintos componentes de un servidor ESXi, y vSphere Proactive HA puede detectar las condiciones de hardware de un servidor.
Por ejemplo, se puede notificar a HA proactiva que hay problemas con la fuente de alimentación de un servidor ESXi. Las máquinas virtuales siguen funcionando en este servidor, pero este problema puede provocar pronto un fallo del servidor. Para evitar posibles fallos de las máquinas virtuales, vSphere Proactive HA puede iniciar la migración de las máquinas virtuales a otros hosts ESXi de un clúster. La HA proactiva permite reaccionar ante problemas relacionados con la fuente de alimentación, el ventilador, el almacenamiento, la memoria y la red.
Es necesario activar y configurar Distributed Resource Scheduler (DRS) en un clúster vSphere antes de poder activar la HA proactiva. Puede configurar vSphere HA y DRS juntos para un clúster.
Reflexiones finales
La potencia, resiliencia y escalabilidad reales de la plataforma VMware vSphere ESXi se desbloquean una vez que se aprovisiona vCenter Server y se añaden los hosts ESXi a un clúster vSphere ESXi. Configure vSphere HA y DRS para proporcionar una protección eficaz contra los fallos de host, así como para equilibrar y programar los recursos para las máquinas virtuales. Tanto DRS como HA son aún más potentes desde vSphere 6.5, ya que VMware ha añadido una supervisión y una visión más proactivas e inteligentes a estas dos funciones de clúster, lo que les permite ser ágiles y proactivas.
No olvide hacer backups de VMware VM aunque sus VMs estén funcionando en el cluster para evitar pérdidas de datos.



